发布日期:2023-12-09 11:58 点击次数:170
kaiyun体育  kaiyun体育
kaiyun体育
从 BERT 到 GPT-2 再到 GPT-3,大模子的畛域是一说念看涨,推崇也越来越惊艳。增大模子畛域仍是被讲明是一条可行的校正旅途,况且 DeepMind 前段时间的一些说合标明:这条路还莫得走到头,络续增大模子依然有着可不雅的收益。
但与此同期,咱们也知说念,增大模子可能并不是擢升性能的独一说念径,前段时间的几个说合也讲明了这少量。其中比拟有代表性的说合要数 DeepMind 的 RETRO Transformer 和 OpenAI 的 WebGPT。这两项说合标明,若是咱们用一种搜索 / 查询信息的面目来增强模子,小少量的生成话语模子也能达到之前大模子能力达到的性能。
在大模子一统寰宇的今天,这类说合显得相等难能贵重。
在这篇著述中,擅长机器学习可视化的知名博客作家 Jay Alammar 把稳分析了 DeepMind 的 RETRO(Retrieval-Enhanced TRansfOrmer)模子。该模子与 GPT-3 性能超过,但参数目仅为 GPT-3 的 4%。

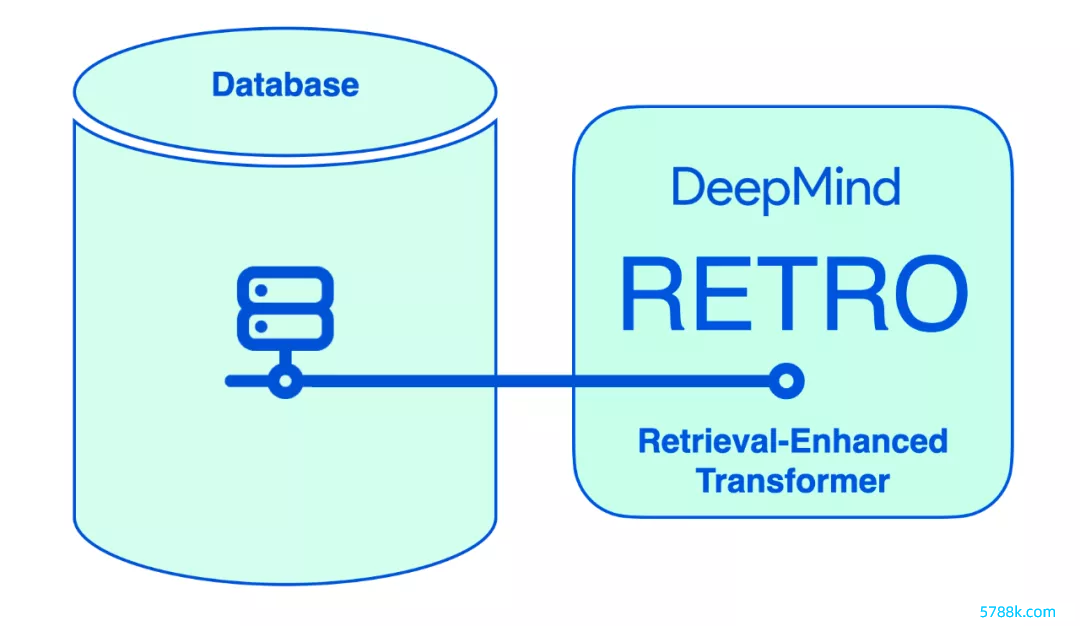
RETRO 整合了从数据库中检索到的信息,将其参数从兴盛的事实和天下常识存储中自若出来。
在 RETRO 之前,说合社区也有一些使命袭取了近似的法子,因此本文并不是要解释它的新颖性,而是该模子自己。
将话语信息和天下常识信息永诀开来
一般来讲,话语模子的任务即是作念填空题,这项任务偶然候需要与事实关系的信息,比如

但偶然候,若是你对某种话语比拟熟悉,你也不错径直猜出空缺部分要填什么,举例:

这种区别相等紧迫,因为大型话语模子将它们所知说念的一切齐编码到模子参数中。天然这关于话语信息是挑升想的,但是关于事实信息和天下常识信息是无效的。加入检索法子之后,话语模子不错收缩好多。在文本生成经过中,神经数据库不错匡助模子检索它需要的事实信息。
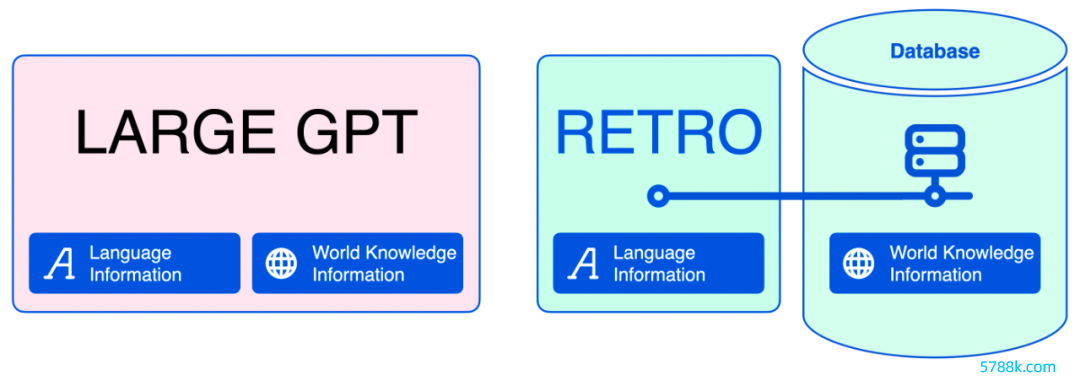
跟着矜重数据系念量的减少,咱们不错使用较小的话语模子来加快矜重。任何东说念主齐不错在更小、更低廉的 GPU 上部署这些模子,并凭据需要对它们进行调遣。
从结构上看,RETRO 是一个编码器 - 解码器模子,就像原始的 Transformer。但是,它在检索数据库的匡助下加多了输入序列。该模子在数据库中找到最可能的序列,并将它们添加到输入中。RETRO 期骗它的魅力生成输出议论。
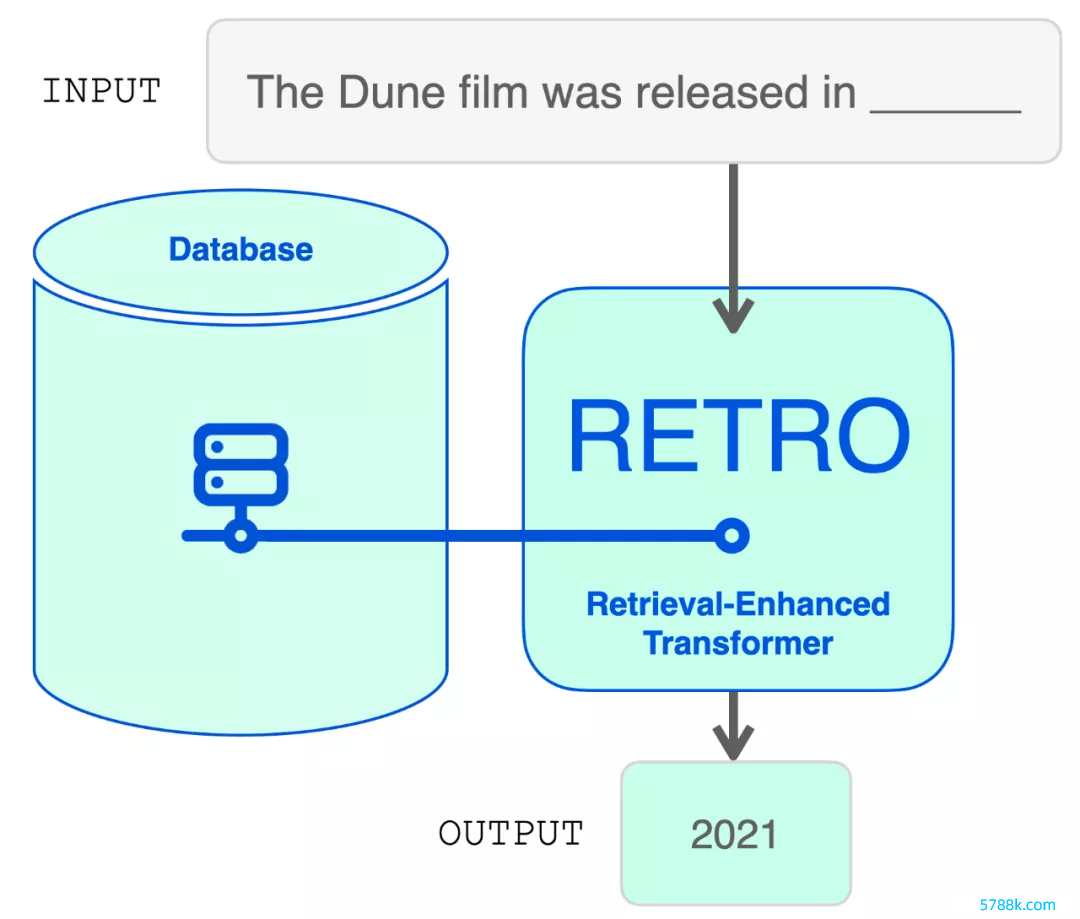
在探索模子架构之前,让咱们先潜入挖掘一下检索数据库。
RETRO 的检索数据库此处的数据库是一个键值存储(key-value store)数据库。其中 key 是法式的 BERT 句子镶嵌,value 是由两部分组成的文本:
Neighbor,用于筹算 key; Completion,原文献中语本的延续。RETRO 的数据库包含基于 MassiveText 数据集的 2 万亿个多话语 token。neighbor chunk 和 completion chunk 的长度最多为 64 个 token。

RETRO 数据库里面展示了 RETRO 数据库中键值对的示例。
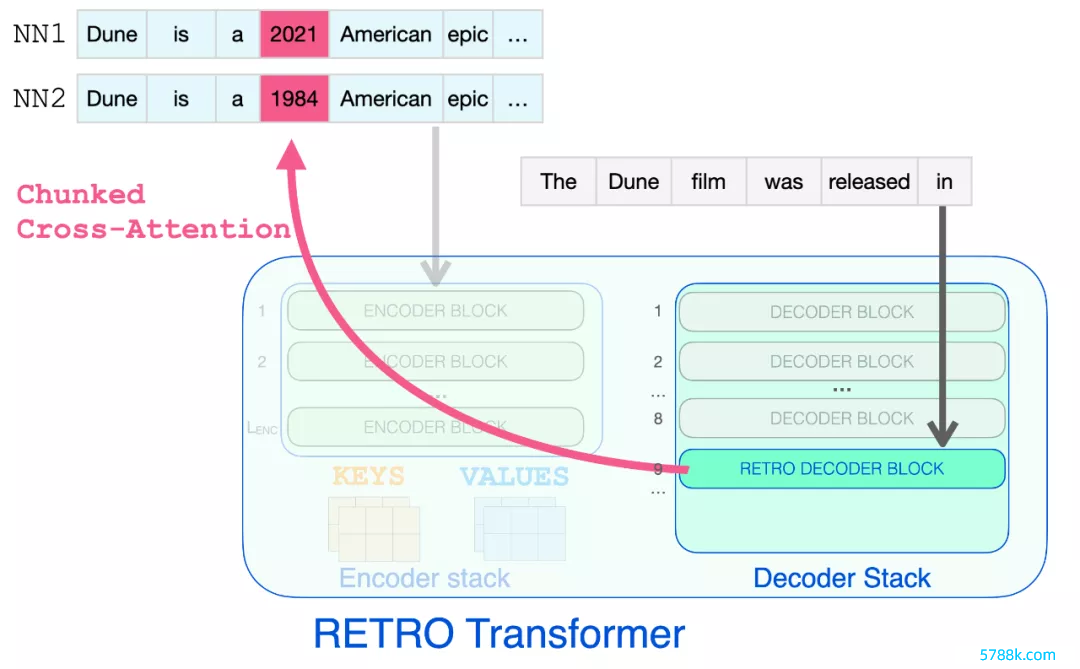
RETRO 将输入指示分红多个 chunk。为简便起见,此处要点热心奈何用检索到的文本试验一个 chunk。但是,模子会针对输入指示中的每个 chunk(第一个 chunk 以外)扩展此经过。
数据库查找在点击 RETRO 之前,输入指示参加 BERT。对输出的盘曲文向量进行平均以构建句子镶嵌向量。然后使用该向量查询数据库。
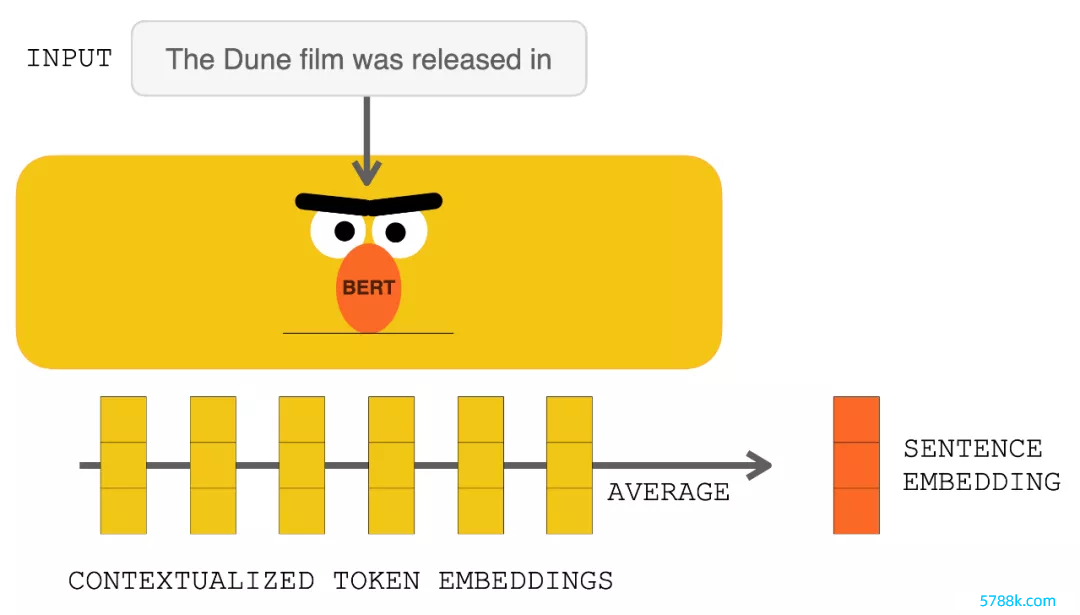
使用 BERT 惩处输入指示会生成盘曲文化的 token 镶嵌 。对它们求平均值会产生一个句子镶嵌。
然后将该句子镶嵌用于近似最隔壁搜索。检索两个最隔壁,它们的文本成为 RETRO 输入的一部分。
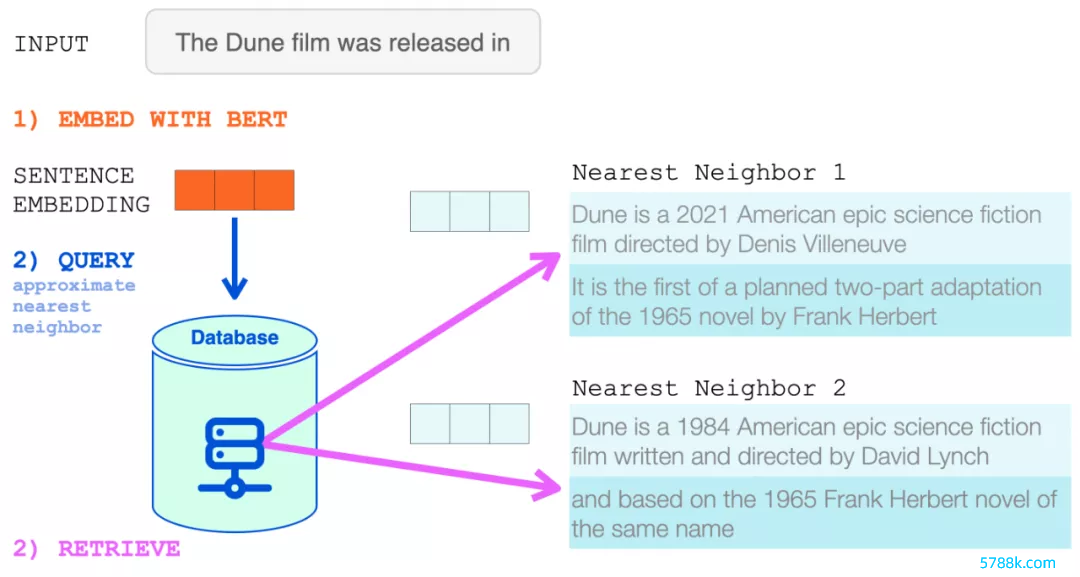
BERT 句子镶嵌用于从 RETRO 的神经数据库中检索最隔壁。然后将这些添加到话语模子的输入中。
咫尺 RETRO 的输入是:输入指示过火来自数据库的两个最隔壁(过火延续)。
从这里运行,Transformer 和 RETRO 块将信息归拢到它们的惩处中。
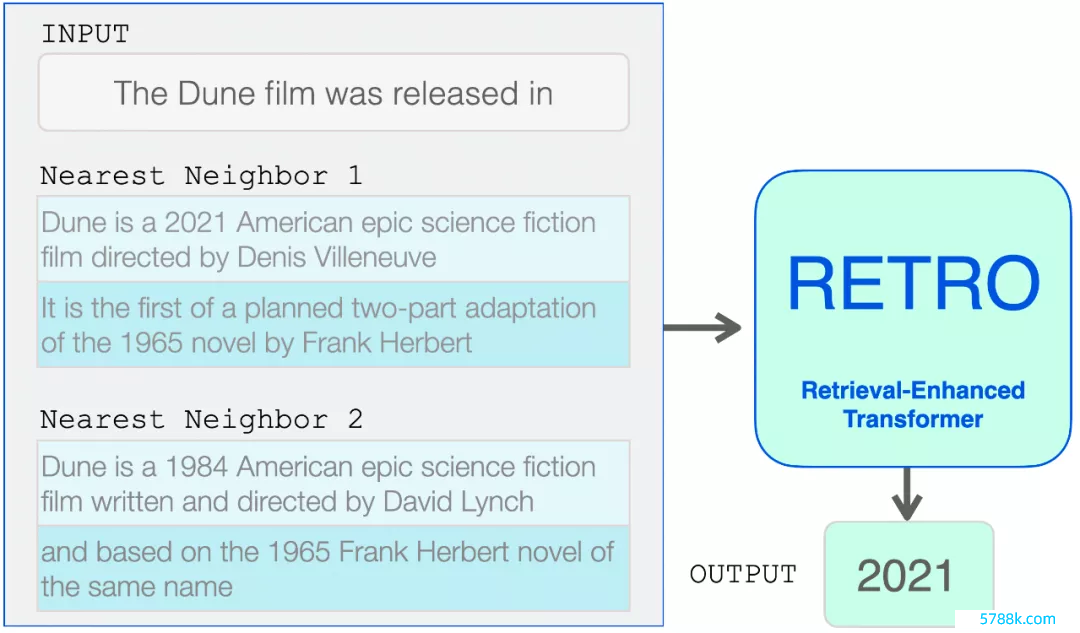
检索到的隔壁被添加到话语模子的输入中。但是,它们在模子里面的惩处面目略有不同。
高眉目的 RETRO 架构
RETRO 的架构由一个编码器堆栈和一个解码器堆栈组成。
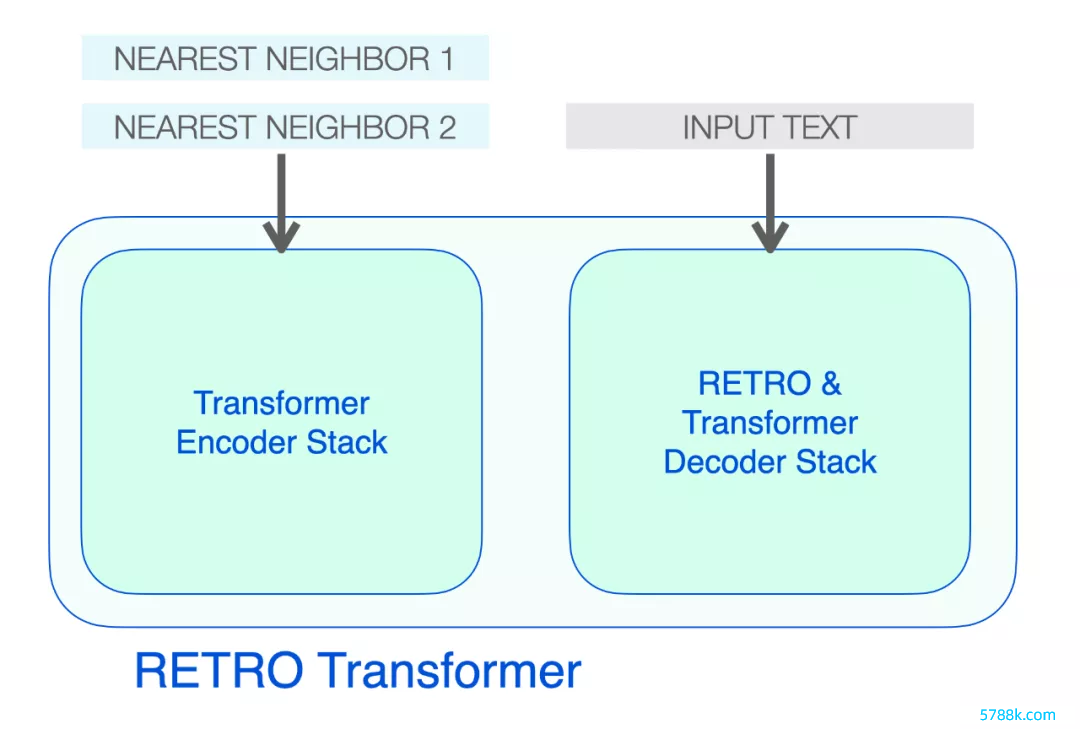
RETRO Transformer 由一个编码器堆栈(惩处隔壁)和一个解码器堆栈(惩处输入)组成
编码器由法式的 Transformer 编码器块(self-attention + FFNN)组成。Retro 使用由两个 Transformer 编码器块组成的编码器。
解码器堆栈包含了两种解码器 block:
法式 Transformer 解码器块(ATTN + FFNN) RETRO 解码器块(ATTN + Chunked cross attention (CCA) + FFNN)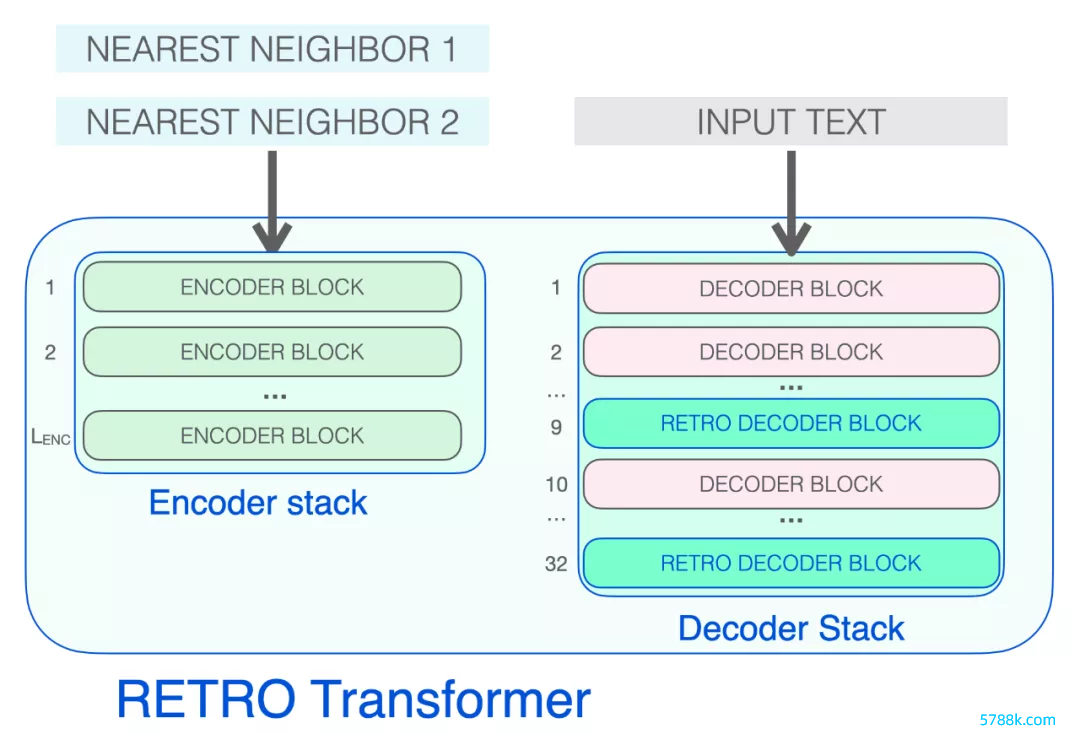
组成 RETRO 的三种 Transformer 模块
编码器堆栈会惩处检索到的隔壁,生成后续将用于提防力的 KEYS 和 VALUES 矩阵。
解码器 block 像 GPT 相同惩处输入文本。它对指示 token 应用自提防力(因此只热心之前的 token),然后通过 FFNN 层。
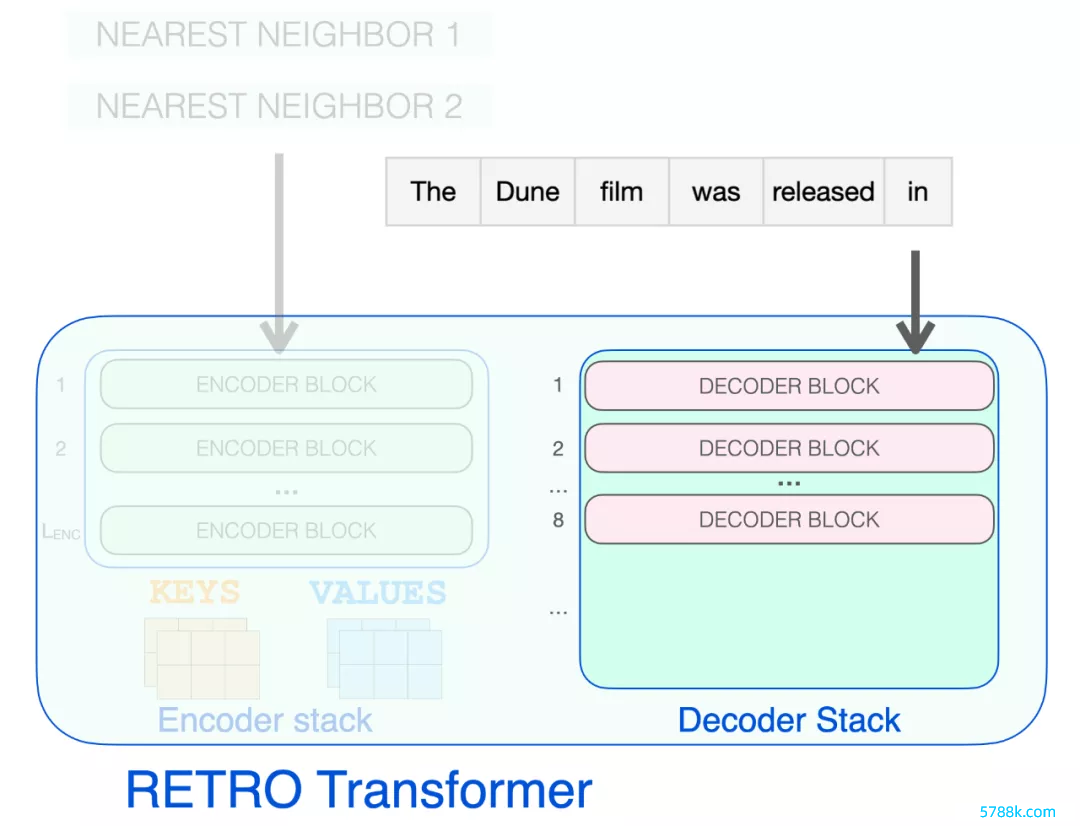
唯有到达 RETRO 解码器时,它才运行归拢检索到的信息。从 9 运行的每个第三个 block 是一个 RETRO block(允许其输入热心隔壁)。是以第 9、12、15…32 层是 RETRO block。
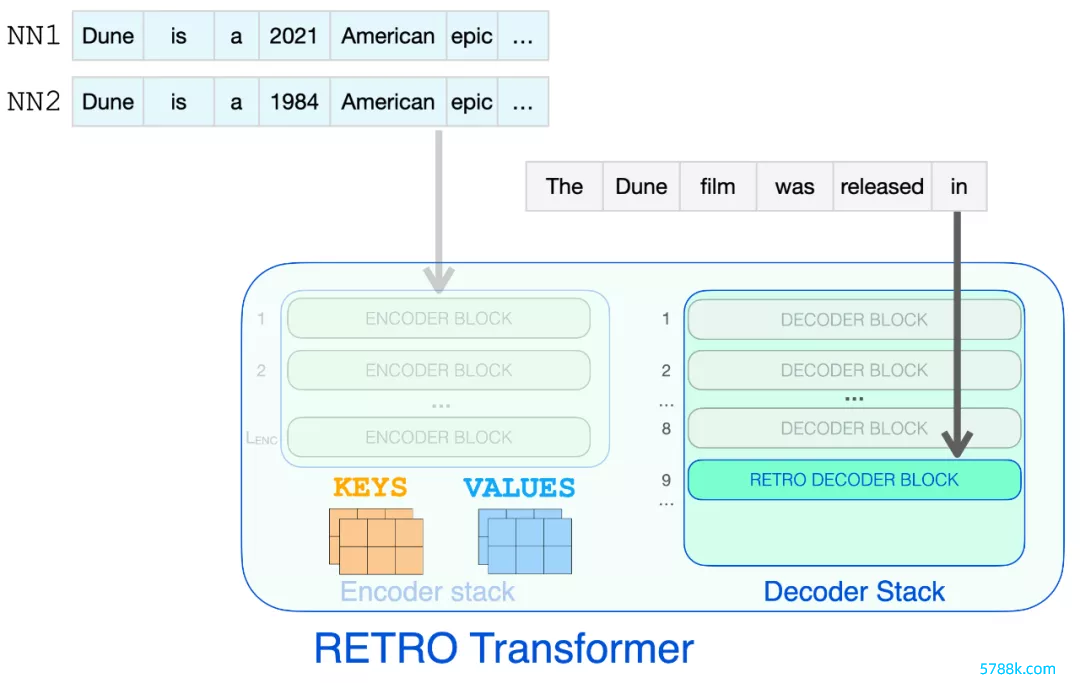
下图展示了检索到的信息不错浏览完成指示所需的节点手艺。